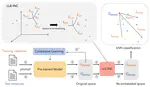
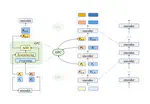
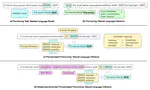
In this paper, we propose a method to enhance in-silico molecule discovery in low-resource settings by using pseudo data generated by Large Language Models (LLMs), demonstrating its efficiency through improved performance, smaller model size, less data, and lower costs, with benefits increasing as more pseudo data is used.